Im Gegensatz zu der an Schulen verbreiteten Methode des »close reading«, hat der Trend zum »distant reading« noch kaum Fuß fassen können. Der in den USA lehrende Romanist Franco Moretti untersucht damit »wiederholbare semantische, grammatikalische Muster in einer großen Textmasse«. Dazu verwendet er Methoden der Datenanalyse, um etwa 15’000 Romane zwischen 1700 und 1900 daraufhin zu untersuchen, welche Gefühle mit welchen Stadtteilen Londons verbunden sind. Moretti hat auch schon mit einer Netzwerkanalyse gearbeitet, bei der Gespräche in einem Drama ein Netzwerk zwischen Protagonistinnen und Protagonisten bilden. So konnte er mit einer Datenanalyse die Wichtigkeit der Figuren bei Hamlet errechnen – dass Hamlet und Horatio die ersten beiden Plätze einnehmen, ist für aufmerksame Leserinnen und Leser nicht besonders erstaunlich.
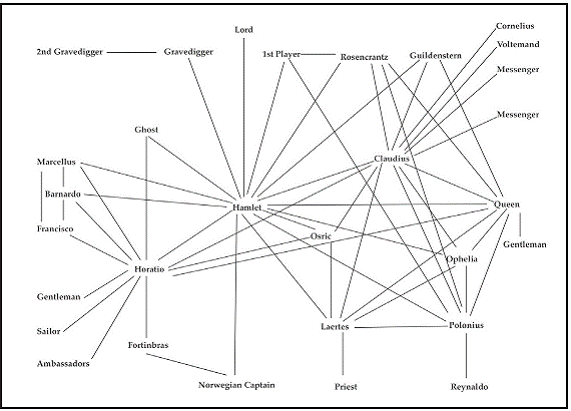
Moretti geht es aber darum, eine Brücke zu schlagen: Zwischen dem »Neuen und dem Alten«, zwischen Interpretation und Big-Data-Verfahren, zwischen der Silicon-Valley-Kultur und der wissenschaftlichen. Er arbeitet auch bei der Datenerfassung oder –visualisierung oft mit händischen Methoden, bildet Hypothesen, die er mit technischen Verfahren überprüft, beschäftigt sich mit methodischen Fragen.
Solche Zugänge sind in den letzten Jahren für die Geisteswissenschaften bedeutsam geworden: Die Digital Humanities haben das Interesse viele Forscherinnen und Forschern auf sich gezogen. Da ihre Verfahren sowohl an die Programm- wie an die Deutungsseite hohe Anforderungen stellen, ist nicht auf Anhieb klar, wie diese Ansätze für die Schule fruchtbar gemacht werden können.
Martin Leubner hat gezeigt, wie digitale Literatur im Deutschunterricht zum Aufbau von Kompetenzen genutzt werden kann, wenn etwa erzähltheoretische Probleme in der Untersuchung von Kleists Marquise von O. mithilfe von Suchfunktionen und Tag-Clouds, also Darstellungen der häufig verwendeten Wörter, untersucht werden. Schülerinnen und Schüler werden dabei digitale unterstützt, bei der Lektüre eigene literaturwissenschaftliche Hypothesen zu bilden und sie mit entsprechenden Methoden zu überprüfen.

Neben den quantifizierenden Verfahren von Suchanfragen (wie oft wird ein Begriff in einem Text verwende?) und der Visualisierung von Worthäufigkeiten mit Tag-Clouds (hilfreiches Tool: wortwolken.com) bietet sich das NGram-Tool von Google für die Durchsuchung von ganzen Korpora an (vgl. für diese Einführung). Verschiebungen in der Begrifflichkeit aufgrund literarhistorischen Verschiebungen können so augenfällig werden. Der Ngram-Viewer kann ähnlich wie die beiden anderen Verfahren immer wieder eingesetzt werden, um Hypothesen zu entwickeln oder zu überprüfen. Bei der Arbeit mit literarischen Texten oder Sachtexten sollte der Bezug auf quantitative Argumente immer wieder geübt werden. Ein sinnvolles Beispiel wäre der Umgang mit Begriffen, die im Kontext der Flüchtlingsdebatte verwendet werden. Welche Wörter verwenden etwa Zeitungen, um flüchtende Menschen zu benennen? Welche Aussagen gibt es von Fachleuten dazu? (Im Hintergrund bietet sich eine Diskussion von Brechts Gedicht Über die Bezeichnung Emigranten von 1937 an.)
Lernende werden durch die Verwendung solcher Tools ermuntert, einerseits kreative Fragen an literarische Texte zu stellen, andererseits einen Einblick in Grundprinzipien der quantiativen Literaturanalyse und eines »distant reading« zu erhalten. Fragen wie die Zusammensetzung der Korpora, der Umgang mit der deutschen Morphologie bei der statistischen Erfassung, der digitalen Aufbereitung von Texten erhalten beim eigenen Experimentieren mit Suchschnittstellen plötzlich eine größere Relevanz.

Abschließend sei aber Moretti noch einmal zitiert, der darauf hinweist, wie sich qualitative und quantitative Methoden ergänzen:
Denn Quantität und Qualität sind nun einmal unterschiedliche Kategorien. Aber natürlich sollte eine quantitative Analyse auch qualitative Aspekte adressieren und sichtbar machen.

4 Kommentare