In den letzten Monaten habe ich mich für ein neues Buch intensiv mit der ganzen Thematik rund um Einflüsse, Verzerrungen und Manipulation im Netz beschäftigt und dazu eine Reihe von Büchern gelesen. Dazu gehört auch »Everybody Lies« von Seth Stephens-Davidowitz, der nach eine kurzen Anstellung bei Google als Journalist bei der New York Times arbeitet.
Die Grundthese des Buches ist recht schnell erklärt: Sozialwissenschaftliche Studien basieren häufig auf Befragungen von Menschen. Diese Befragungen sind oft verzerrt, weil Menschen aus verschiedenen Gründen unwahre Angaben machen (sie erinnern sich schlecht, sie präsentieren ihr Selbstbild statt die Realität, sie wollen einen guten Eindruck machen, sie sind durch die Art der Fragestellung manipuliert etc.). Ein Beispiel aus dem Buch: Heterosexuelle Frauen in den USA geben an, pro Jahr 1.1 Milliarden Kondome zu verwenden; heterosexuelle Männer hingegen 1.6 Milliarden. Was stimmt? Pro Jahren werden 600 Millionen Kondome verkauft.
Stephens-Davidowitz behauptet nun, dass es bessere Daten gäbe, mit denen ein deutlich genaueres Bild von den gesellschaftlichen Verhältnissen gezeichnet werden könne: Suchanfragen im Netz. Auch hier ein Beispiel: Mit eine Karte, auf der die Häufigkeit von rassistischen Suchanfragen verzeichnet sind, kann der Autor zeigen, dass die amerikanischen Wahlen durch Rassismus stark beeinflusst sind, so stark, dass sich dadurch auch der Wahlerfolg von Donald Trump erklären lässt.
Die Suchdaten, so seine Formulierung, seien ein »truth serum«, also ein Wahrheitstrank, mit dem es möglich sei, unbewusste und geheime Gedankengänge von Menschen nachzuvollziehen. Während Social Media eine inszenierte Außenseite präsentiere (mit der auch durch Datenauswertung keine soliden Einsichten gewonnen werden könnten), zeigten die Suchanfragen das, was Menschen wirklich bewege.
Ein Grund dafür ist auch, dass Menschen die Suche auch für intime oder tabuisierte Themen verwenden. Der Autor hat etwa Humor (die Suche nach Witzen) untersucht oder, wie unten dargestellt, Abtreibung: In Bundesstaaten, in denen es in den USA schwierig ist, Abtreibungen legal vorzunehmen, gibt es deutlich mehr Suchanfragen zu selbstinduzierten Aborten, die kaum statistisch sinnvoll dokumentiert sind.
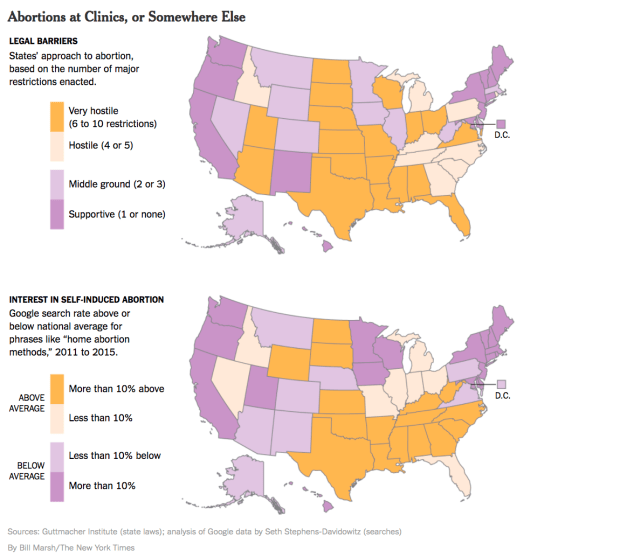
Das sind alles sehr hübsche Ergebnisse, die sich gut lesen. Doch leider überschätzt der Autor seine Methode. Das zweite Kapitel, in dem es um eine Überprüfung von Freuds Aussagen geht, untersucht etwa, ob phallusförmige Früchte- und Gemüsesorten in den Träumen von Menschen häufiger auftreten als andere. Das auf der Basis von Suchanfragen zu untersuchen, ist wenig hilfreich, weil schon die Fragestellung an sich keine sinnvolle empirische Prüfung von Freuds Annahmen und Aussagen zulässt.
Stärker sind die Passagen, in denen Stephens-Davidowitz vorführt, wie die Datenauswertung konkret funktioniert. Dass z.B. die Suche nach Doppelgängern im Sport oder in anderen statistischen Bereichen Zusammenhänge und Prognosen aufzeigen kann, die sich dem wissenschaftlichen Verständnis noch entziehen: Es ist also zielführend, sich zu überlegen, welchem historischen Beispiel eine aktuelle Situation oder eine Person gleicht, um dann Annahmen über ihre Entwicklung treffen zu können. Ein Beispiel dafür sind Empehlungsalgorithmen, die sich weniger auf vergangene Käufe stützen sollten, sondern sich an ähnlichen Käuferinnen und Käufern orientieren könnten, um gute Vorschläge zu machen.
Auch die Formulierung, Big Data erlaube das Reinzoomen in Datensätze ist verständlich aufgearbeitet und mit guten Beispielen belegt. Doch die Konsequenz, dass es sich bei der Arbeit mit Daten und Suchanfragen um »echte Wissenschaft« handle, während alle anderen sozialwissenschaftlichen Bemühungen sinnlos seien, lässt sich argumentativ mit dem Buch kaum stützen. Stephens-Davidowitz hat aus einigen guten Beispielen zu Erkenntnissen aus Suchanfragen ein Buch gemacht, mit dem er zu hohe Ansprüche formuliert. Die Hoffnung, der Zugriff auf Daten lasse die Wissenschaft erblühen, ist zu Zeiten der Replikationskrise irreführend, zumal viele der verwendeten Daten nicht in experimentellen Settings erworben worden sind und ohne die sehr selektiven Zugriffe der Unternehmen, welche die Daten gesammelt haben, gar nicht verfügbar.
Die Daten zu Google-Suchanfragen gehören in die Öffentlichkeit, damit sie zu Forschungszwecken genutzt werden können. Aber ob sie die Sozialwissenschaft revolutionieren werden, wage ich zu bezweifeln.
